


DATA Provisioning in SAP HANA
SAP HANA is a database and whenever it is used for analytics, it might require data to be channeled to it from all the systems where business transactions are going on. I used the word “might” in the previous sentence because with SAP’s new S4HANA application, analytics and transactions can now take place on the same database. Check it out on this link on the SAP website – It’s quite amazing. I will do a document on it once I have created all the basic tutorials for the topics here. S4HANA is great but still not widely adopted. The more common techniques of data analysis involve data provisioning from external systems into HANA for modeling. Let’s take a look into these methods one by one.
1. Flat file upload
Flat files are data files which are stored locally and not coming in from a live server. The supported extensions are .csv, .xls and .xlsx . So if you add a few columns of data in excel and save as one of these formats, it is now a flat file ready for upload. This is the least used method in HANA as business data should ideally come from live transactional database tables rather than static files.


These type of files are usually used for custom table data loads wherein sometimes the business wishes to maintain some mappings or so. For example, let’s say that our client has 2 source systems – one for the US and one for Germany and they maintain different status values for the same status. In the US an open order in source system is denoted by “OP” and in Germany (DE is for Deutschland which is how the true German name for Germany), the open orders are denoted by OF. In this case, if we are creating a global report, it’s not good to have two symbols for the same meaning. Therefore, someone from the client team makes a target mapping saying that “OP” will be the final target value for such ambiguities and in HANA we use this mapping table to harmonize the data. Such files are usually uploaded via flat files into HANA into custom tables as source systems may not have them maintained anywhere especially if each of these countries have a different system.
| Country | Order (Source) | Order (Target) |
| US | OP | OP |
| DE | OF | OP |
We will learn on the different ways to do this in further tutorials.
2. SLT Data provisioning
SAP Landscape Transformation or SAP SLT is the most widely used data provisioning technique for native SAP HANA projects with SAP source systems. Most tutorial spread the misconception that developers manage the replication but usually it will be an administrator who will take up the request for table replication from a developer and then make sure that table is replicated as there may be security restrictions on the incoming data and it’s not difficult to mess up SAP SLT replication if the entire control is given to a newbie developer. Thus from a developer perspective, let me keep the explanation simple for now.
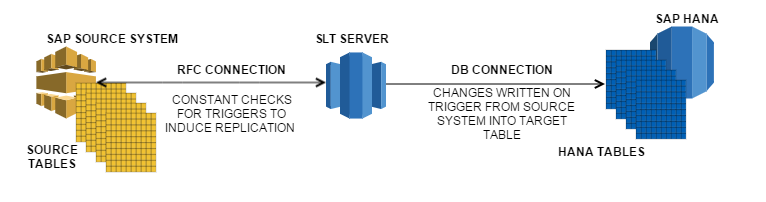

As seen in the illustration, when a SLT server and its connections have been properly set up between the SAP source system and HANA, there is a state of constant replication between source and target HANA system. Every time there is a change in the table, a trigger from source pushes the data through the SLT server to HANA. The initial load of tables might take some time as there may be millions of records in most financial and sales tables but after that has been done, the replication is done in near real-time speeds (most would refer to this as real-time as there’s only a few seconds of delay).
3. SAP Data services (BODS)
DataServices or BODS is an amazing tool which can take data from any data source to any data target. It is one of the most powerful ETL tools out there in the market and since it’s an SAP product now, the integration is really smooth. You have different options here for transforming data coming in from source systems before it reaches the target HANA table. There are set of rules that can be created and run by scheduled jobs to keep data updated in HANA. But although BODS does support real-time jobs, usually batch jobs (=scheduled background jobs) are run due to performance limitations. This means that this provisioning technique is not real-time. The newer versions of SAP BODS also support creating repositories on SAP HANA this allowing many calculations to be performed in the HANA database. But in most such implementations involving SAP BODS, data transformations are usually done in HANA data models rather than data services to have all the logic at one place. We will do a demo soon on this in a separate tutorial.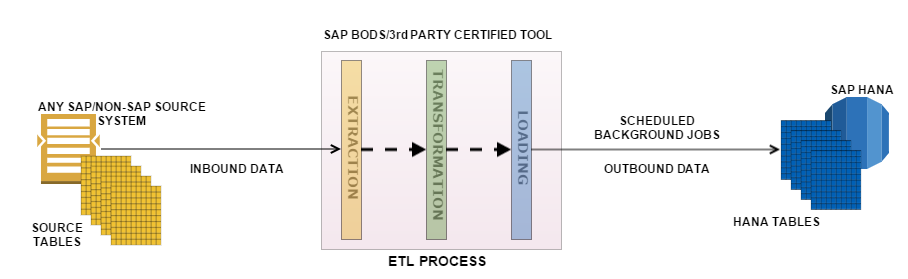

4. Other certified ETL tools
Like BODS, there are other powerful ETL vendors in the market that do similar jobs but they need to be certified with SAP for your client to get any type of support from them if something goes wrong. Why would you go for such options? Well, if your client was having an architecture that already had licenses for these tools, then they would want to use it instead of shelling out more money for SAP data provisioning licenses. But since these won’t be SAP tools, the integration would not have as many options to play around with as the SAP ones.
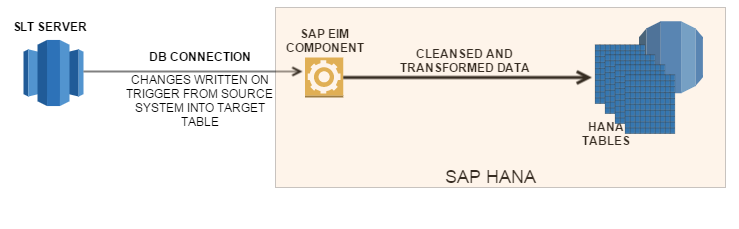
5. SAP EIM (Enterprise Information Management)
This combines the SLT and BODS approaches and is a relatively new feature. SLT brings in new data at real-time and EIM has a subset of tools from BODS for major data cleansing and transformations. This is a great option but still in a relatively native stage and hence the usage is still not widespread also since it might require extra licenses and hence additional cost.

6. Smart Data Access
Smart data access may not be exactly a data provisioning technique as there is no data being replicated as this method involves replication of table meta-data only from the source and not its data. This means that you get the table structure on which you can create a “Virtual table” for your developments. This table looks and feels exactly like the source table with the difference that the data that appears to be inside it is actually not stored in HANA but remotely in its source system. HANA supports SDA for the following sources: Teradata database, SAP Sybase ASE, SAP Sybase IQ, Intel Distribution for Apache Hadoop and SAP HANA. SDA also does an automatic datatype conversion for fields coming in from source system to HANA datatype formats.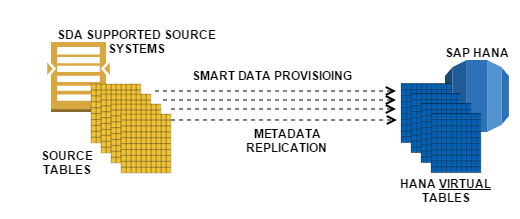

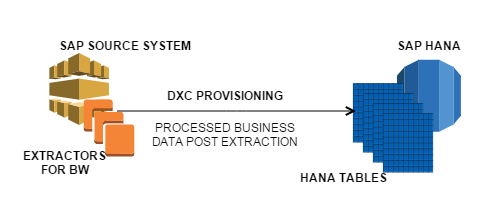
7. DXC or Direct Extractor Connection
You would need to have some SAP BW background to fully understand this. Give it a read and don’t bother if you don’t get too much of it. This data provisioning technique involves leveraging the extractor logic in SAP source systems and to process the incoming data through that layer of logic in the SAP source before being delivered to HANA. This of course involves execution of quite some logic in ECC side and is not recommended. I personally am not a fan of this method and haven’t seen any client be inclined towards it either. It is a waste of HANA’s potential in my honest opinion. You are better off spending time gathering raw requirements, and building the views from scratch than using this bad shortcut.

Please show your support for this website by sharing these tutorials on social media by using the share buttons below. Stay tuned for the next ones.
Happy learning!